Figure 9.1 shows a clustering of a two-dimensional point data set with two clusters: The leftmost cluster, whose points are marked by asterisks, is some- what diffuse, while the rightmost cluster, whose points are marked by circles, is compact. To the right of the compact cluster, there is a single point (marked by an arrow) that belongs to the diffuse cluster, whose center is farther away than that of the compact cluster. Explain why this is possible with EM clustering, but not K-means clustering.
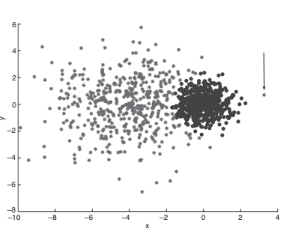
In EM clustering, we compute the probability that a point belongs to a
cluster. In turn, this probability depends on both the distance from the
cluster center and the spread (variance) of the cluster. Hence, a point that
is closer to the centroid of one cluster than another can still have a higher
probability with respect to the more distant cluster if that cluster has a higher
spread than the closer cluster. K-means only takes into account the distance
to the closest cluster when assigning points to clusters. This is equivalent to
an EM approach where all clusters are assumed to have the same variance.
You might also like to view...
To add a custom property, click it in the list or type a new property in the ____ box.
A. Custom B. Property C. Presentation D. Name
Relational expressions are also known as ____.
A. conditions B. boolean expressions C. logical expressions D. if-else expressions