Repeat the analysis for part (c) using the same cutoff threshold on model M2. Compare the F-measure results for both models. Which model is better? Are the results consistent with what you expect from the ROC curve?
You are asked to evaluate the performance of two classification models, M1
and M2. The test set you have chosen contains 26 binary attributes, labeled
as A through Z.
Table 5.5 shows the posterior probabilities obtained by applying the models to
the test set. (Only the posterior probabilities for the positive class are shown).
As this is a two-class problem, P(?)=1 ? P(+) and P(?|A, . . . , Z)=1 ?
P(+|A, . . . , Z). Assume that we are mostly interested in detecting instances
from the positive class.
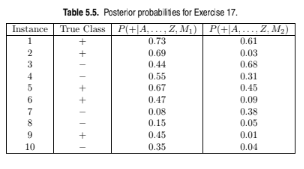
When t = 0.5, the confusion matrix for M2 is shown below.
![]()
Precision = 1/2 = 50%.
Recall = 1/5 = 20%.
F-measure = (2 × .5 × .2)/(.5 + .2) = 0.2857.
Based on F-measure, M1 is still better than M2. This result is consis-
You might also like to view...
When you import an outline from Word into PowerPoint, the font that will be used by default in PowerPoint is ________
A) Times New Roman B) Arial C) the font that was used in the Word outline D) the default font of the theme you choose
An example of a ________ is (C5+D5 )/100
A) formula B) text string C) named range D) function