Repeat for the two children of the root node.
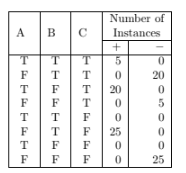
The following table summarizes a data set with three attributes A, B, C and
two class labels +, ?. Build a two-level decision tree.
Because the A = T child node is pure, no further splitting is needed.
For the A = F child node, the distribution of training instances is: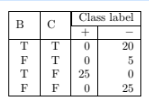
The classification error of the A = F child node is:
After splitting on attribute B, the gain in error rate is:
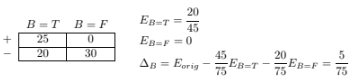
![]()
![]()
Therefore, A is chosen as the splitting attribute.
You might also like to view...
There is no limit to the number of scenarios that can be created with Scenario Manager
Indicate whether the statement is true or false
?Cultural conventions, which are generally the same from one country to the next, do not need to be taken into consideration when developing a website for use internationally.
Answer the following statement true (T) or false (F)